
SemVer 2.0
and ways to make it useful

Versioning and the release process is tightly coupled. Because releasing something means delivering snapshots of the same service throughout a long period of time. And different snapshots need a unique identifier.
There is a several approaches to naming a version, like hashing, date and time of release, or increment of numbers, but for some reason, semantic versioning is one of the most popular of them.
Let’s figure out what we can cook with it. But first here is a quick referance for the rules:
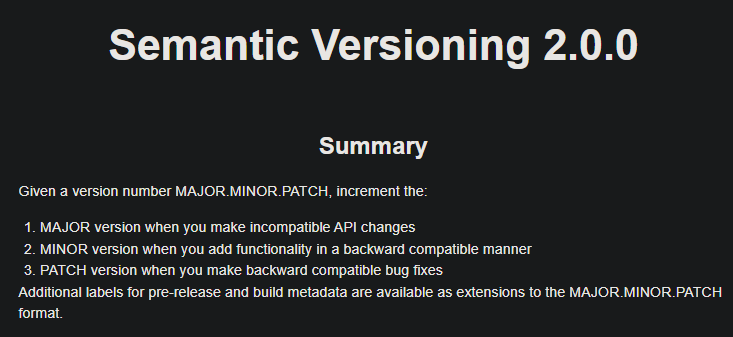
So, you make a company-wide policy so that engineers will now decide on the version naming.
Everyone happy! Now we have a reliable way of versioning things, right?
R-right?

Aaaannnnd… the engineer never actually followed any rules.
It’s simple, yet there is so much bias happening when you give people power to change the version.
Architects want to reward themself for big migrations facilitated
Devs want to celebrate big refactoring or big chunks of work done
PMs want a major version after every epic.
There is nothing particularly bad or abnormal with people's desire to mark the big effort behind their work with a numbered version. But my points is, if you changed the whole service and no API was affected:
You did a great job designing APIs
It’s a patch change

The real-world semantic versions are ugly. And there is so much pursuit of beauty in engineering; following those rules just feels wrong, even counterintuitive.
You need to be prepared for the fact that a few years deep into the regular cadence of scheduled project releases, you will have 100+ major version changes in most interconnected and important BE services.
There is just so much professional bias happening, the faultiest, stupiddest implementation of the automatic semantic version assignment will do more reliable work than any engineer ever will.

So, let’s go back to SemVer rules.
The main idea is: will another service notice the difference if we rollback?
For example:
If another service adds a new field in their request and we have not yet introduced it in our API contract deserialization data structure, we can probably just ignore it and move on. But, getting fewer data fields than we require on the input will instantly trigger deserialization errors.
The same goes for the Response DTO; we cannot just “rollback“ the newly added field. Other services are relying on its existence! But bringing back something we freshly removed? Sure, no problems here.
We are not talking about how the internal logic of a service will react to each of these use cases; we are simply checking contract compatibility, like puzzle pieces.
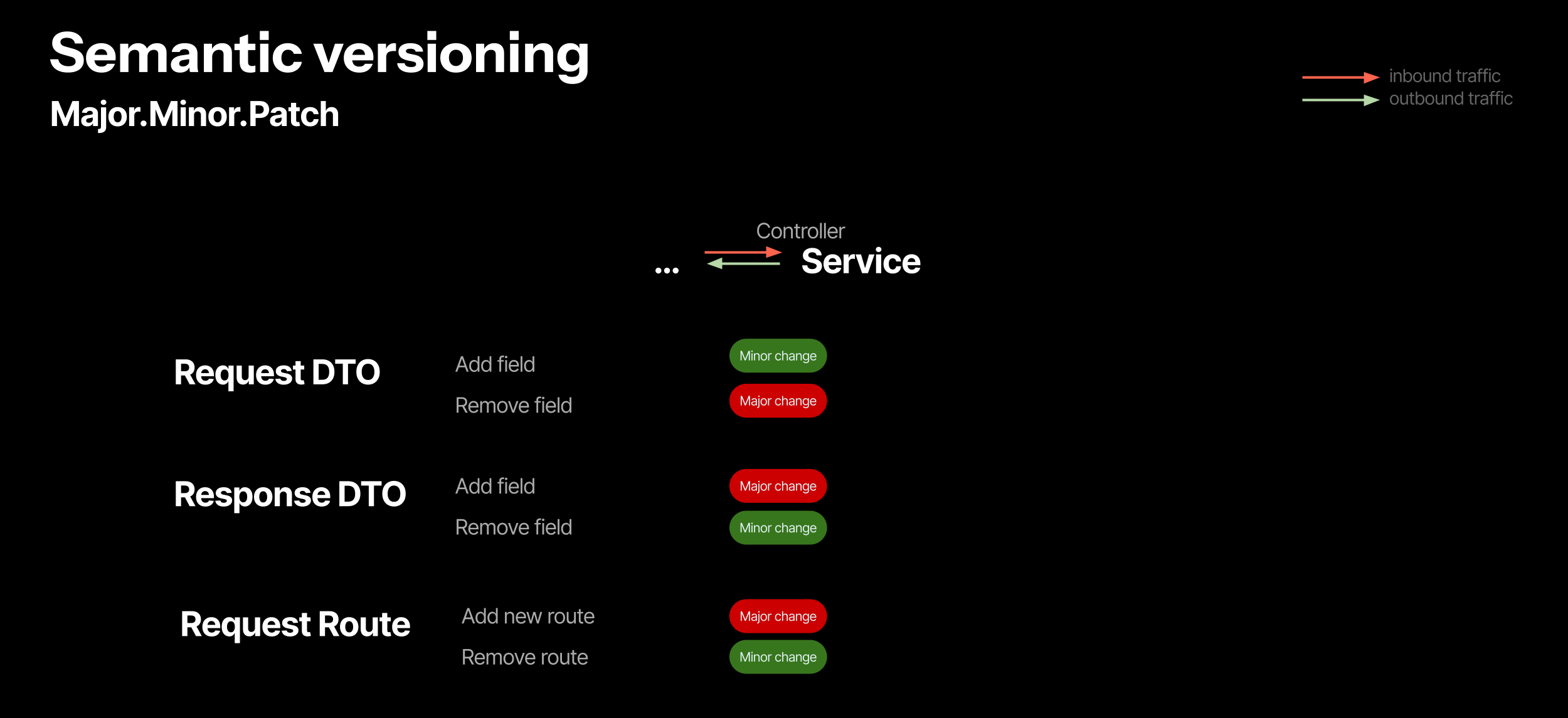
I really like semantic versioning, but it only describes the public API.
If it’s not a library but a service in a structured system, I would also prefer to check the external API we use. Sooo… Let’s upgrade it a bit.
Let’s also add an answer to this question:
”What changes in our representation of the external API is backwards incompatible?”
So we can fully assess the possibility of rollback for this particular service without breaking other services or going into a downtime.
Frankly speaking, it’s the same rules for outbound traffic; they are just reversed.

Changes here have a pattern. The moment you see minor and major version changes on different sides of one API communication route, you know that backwards-incompatible changes were introduced here.
You know that without looking into the code or documentation at all!
You can also understand the direction of changes, because breach of a contract happens when a request moves from Minor → Major version change. Not sure what use you can make from that information.. But hey! To some degree, the surplus of information confirms the accuracy of the source.
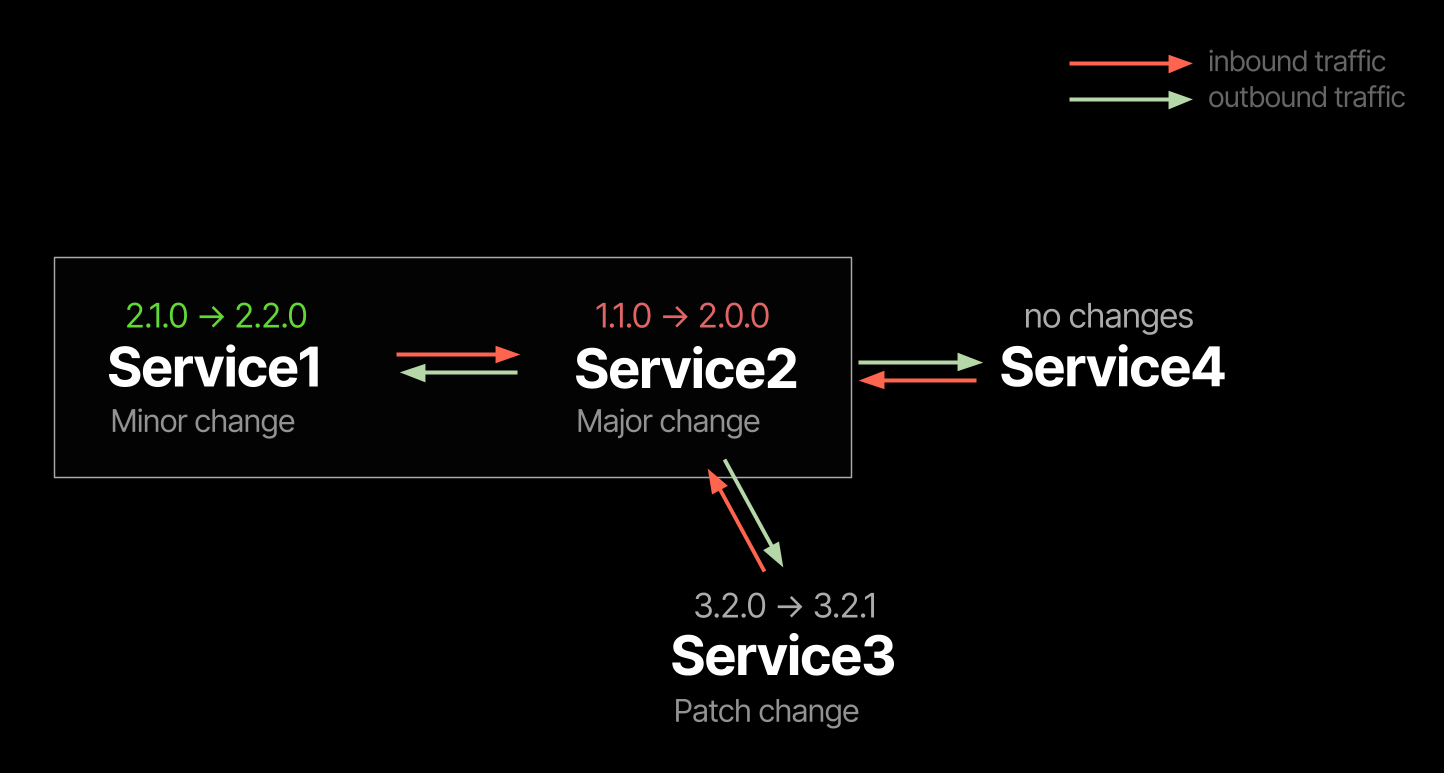
So, if you try to release your services on some synchronized cycle, SemVer++ starts to describe the state of internal communication. It will also give a source of truth about service compatibility, which will help when you move towards a proactive reliability approach.
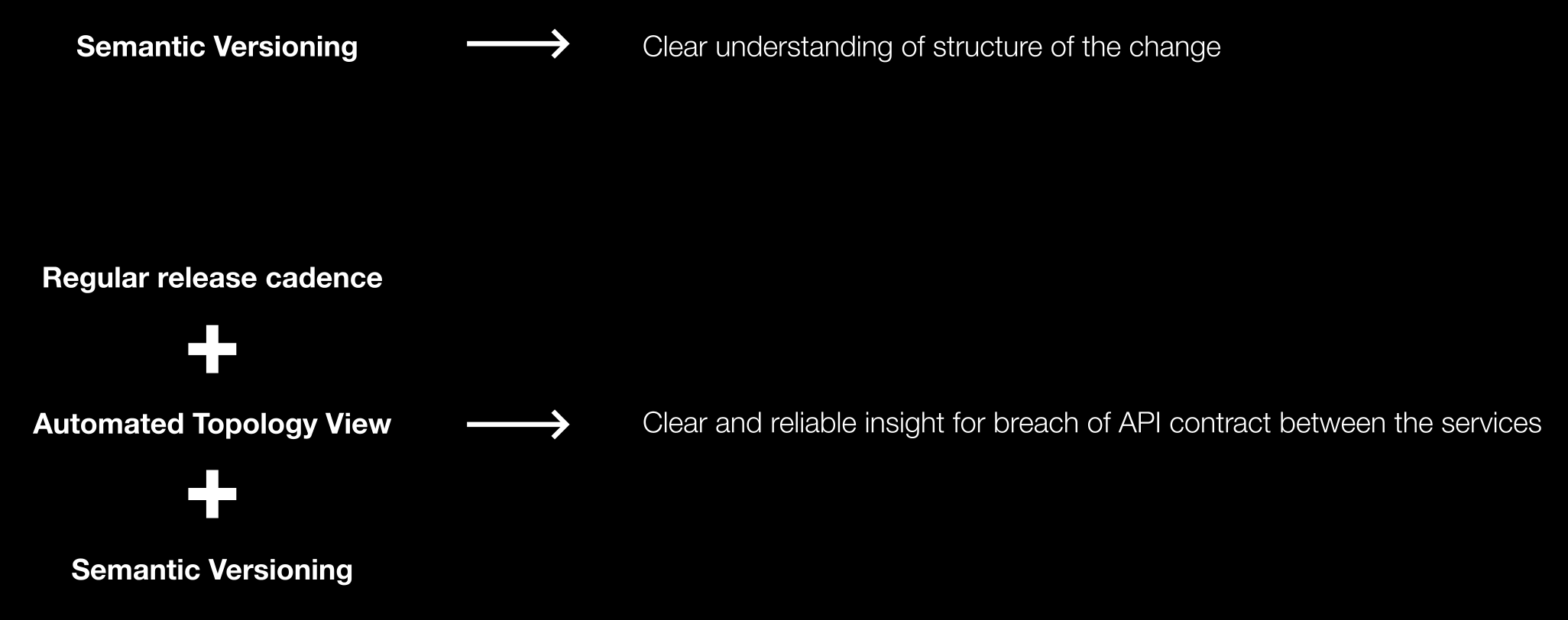
That’s how we use SemVer as a reliable tool!
Now forget about all that shit and just use Protocol Buffers.